Wie Machine Learning Projekte Laufen lernen – 5 Hürden zwischen Theorie und Praxis
on 16.05.2024 by Dr. Matthias Böck, Roua Guesmi

In dieser Blogpost-Serie werden wir die versteckten Elemente aufzeigen, die unserer Meinung nach Unternehmen wie Ihres daran hindern, das Beste aus dem maschinellen Lernen herauszuholen. Wir gehen der Frage nach, warum es vielen Unternehmen nicht gelingt, ihre Nutzung von Systemen für maschinelles Lernen im Laufe der Zeit zu maximieren, warum eine veränderte Denkweise der Schlüssel sein könnte, und erläutern, was unserer Meinung nach der beste Ansatz ist, um die häufigsten Fallstricke zu vermeiden. Wir werden auch Beispiele aus der Praxis und Einblicke von Kunden geben, um Ihnen dabei zu helfen, eine neue Herangehensweise an gängige Herausforderungen des maschinellen Lernens zu finden.
Produktion und Akzeptanz: Die Einführung von Machine Learning ist eine komplexe Aufgabe
Die Entwicklung eines ausgefeilten Algorithmus auf der Grundlage hochwertiger Daten und die Erstellung präziser Vorhersagen sind entscheidende Komponenten eines erfolgreichen Projekts für maschinelles Lernen. Die größten Herausforderungen sind jedoch nach wie vor strategischer oder prozessbezogener Natur, nämlich:
- Stellen der richtigen Fragen
- Deployment und Maintenance von Machine Learning Lösungen in der Produktion
- Organisatorische Annahme und Befähigung eines Unternehmens, es tatsächlich zu nutzen
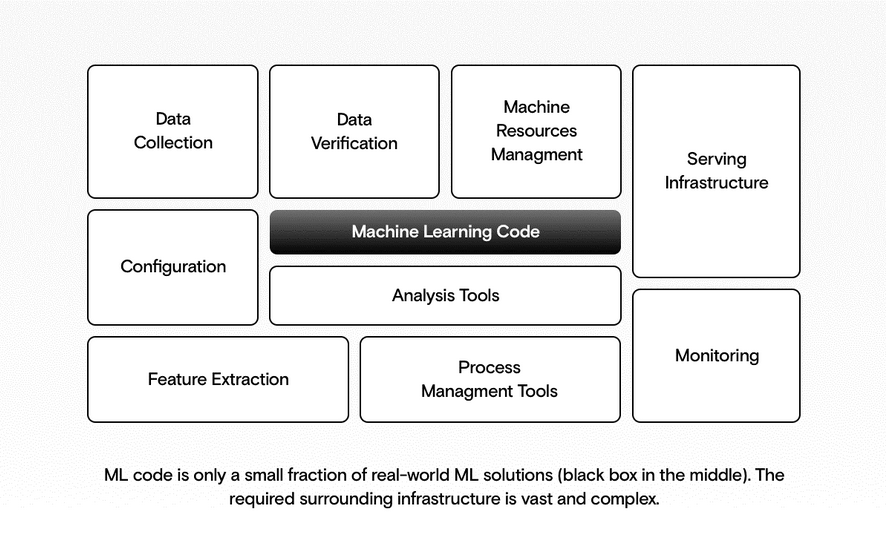
Auf technischer Ebene besteht nur ein kleiner Prozentsatz einer Lösung für maschinelles Lernen tatsächlich aus Machine Learning Code (Training und Bewertung des Modells). Der Rest entfällt auf Aufgaben wie Modellbereitstellung, Wartung, Updates, Experimente, Audits, Versionierung und Überwachung und natürlich auf Tätigkeiten rund um die Datenbasis. Folglich ist die Einführung von Lösungen für maschinelles Lernen in die Produktion eine komplexe Aufgabe, die eine Kombination aus verschiedenen Fähigkeiten und Technologien erfordert.
Überblick über die verschiedenen Bausteine der benötigten Infrastruktur
(https://www.datarevenue.com/en-blog/what-is-machine-learning-a-visual-explanation):
A
Viele Unternehmen haben auf diese Entwicklungen mit umfangreichen Investitionen in ihre Tools und der Anstellung qualifizierter Data Scientists reagiert. Dies half ihnen, tiefere Einblicke in ihre Daten zu gewinnen und modernste Methoden des maschinellen Lernens anzuwenden. Dennoch fällt es ihnen nach wie vor schwer, diese Methoden in die Produktion einzubringen oder mit den jüngsten AI-Entwicklungen Schritt zu halten und deren Potenzial voll auszuschöpfen.
Das liegt vor allem daran, dass sie sich auf eine projektorientierte Denkweise verlassen, anstatt produktorientierte Ansätze anzuwenden. Proof-of-Concepts (POCs) oder Ad-hoc-Analysen helfen Unternehmen, ein besseres Verständnis zu erlangen oder sich für eine bestimmte Initiative zu entscheiden, aber es fehlt ein Plan für die kontinuierliche Entwicklung und Nachhaltigkeit. Dieser Mangel an produktorientiertem Denken äußert sich in der Regel wie folgt:
- Versäumnisse bei der Anpassung von Modellen an Änderungen der Daten oder des angewandten Kontexts
- Unklare Zuständigkeiten für die Wartung und die Wartungsprozesse (Spoiler: in den meisten Fällen sollten nicht Ihre Data Scientists für die laufende Wartung zuständig sein)
- Unzuverlässige Code-Wartung und Versionierung von Daten
- Und das Schlimmste: Lösungen, die nicht zum Einsatz kommen oder den Nutzern keinen Mehrwert bieten.
Technologie und eine Gruppe von Data Scientists allein können diese Probleme nicht lösen.
Gute Datenprodukte erfordern Produktdenken
Eine Lösung für diese Probleme besteht darin, uns die Frage zu stellen: Wollen wir etwas bauen, das von Bestand ist? Oder bauen wir nur einen POC, den wir möglicherweise bald wieder verwerfen werden?
Produktdenken ist ein Framework, das Ihnen hilft, Produkte zu entwickeln, die den Menschen wirklich wichtig sind. Durch die Einbeziehung aller relevanten Interessengruppen in den gesamten Entwicklungsprozess wird der Fokus auf die tatsächlichen Bedürfnisse der Nutzer gerichtet. Dieser nutzerzentrierte Ansatz ist der Grundstein für die Wertschöpfung eines jeden Datenprodukts.
Was ist die Definition eines guten Datenprodukts?
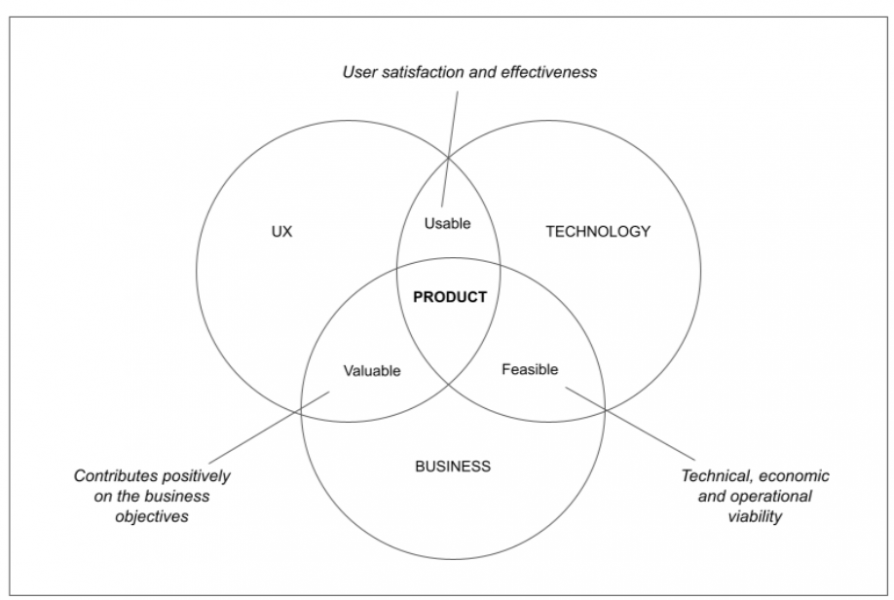
Eine einfache Definition für ein erfolgreiches Produkt ist, dass es sich in der Schnittmenge von wertvoll, machbar und nutzbar bewegen muss. Das bedeutet, dass die Perspektiven der User Experience, der Technologie und des Geschäfts während des Entstehungsprozesses des Produkts harmonisch miteinander verwoben werden müssen. Es gibt mehrere Möglichkeiten, dies zu erreichen, und in dieser Blogpost-Serie geben wir Ihnen einige Beispiele aus der Praxis und Einblicke von unseren Kunden, die Ihnen dabei helfen.
Definition der wichtigsten Aspekte eines Produkts (inspiriert durch die Arbeit von Martin Erikssen):
von dem, was wir für den richtigen Ansatz bei der Entwicklung von Datenprodukten halten, gibt es eine Reihe von externen Herausforderungen bei der Einführung von Systemen für maschinelles Lernen in die Produktion. Wir werden uns nun einige davon ansehen und erläutern, was Sie dabei beachten müssen.
richtige Balance zwischen AI-Funktionen und allgemeiner Wahrnehmung finden
Laut Gartner bleiben selbst bei Unternehmen mit großer KI-Erfahrung 85 % der Projekte für maschinelles Lernen hinter den Erwartungen zurück, und nur 53 % der Projekte gehen erfolgreich vom Prototyp in die Produktion über.
Systeme für maschinelles Lernen scheitern nicht nur auf dem Weg zur Produktion, sondern auch, wenn wir nicht wissen, wie das System von seinen Nutzern verwendet und wahrgenommen wird. Nehmen wir zwei prominente Beispiele von Amazon und Microsoft:
- Amazons Rekrutierungstool
Amazon entwickelte 2014 ein KI-gestütztes Rekrutierungstool, um den Prozess der Identifizierung von Spitzentalenten anhand von Lebensläufen zu automatisieren. Im Jahr 2015 stellten die Experten für maschinelles Lernen des Unternehmens jedoch fest, dass das Tool männliche Bewerber für technische Positionen bevorzugte, da es auf Lebensläufen trainiert wurde, die über einen Zeitraum von zehn Jahren eingereicht wurden und in denen die Mehrheit der Bewerber männlich war. Dieser Vorfall unterstreicht, wie wichtig es ist, KI-Modelle auf unterschiedlichen Datensätzen zu trainieren, um Verzerrungen zu vermeiden. - Dieser Vorfall mag zwar schon ein paar Jahre zurückliegen, aber neuere große Sprachmodelle (wie ChatGPT) verwenden (neben anderen Daten) auch Daten aus sozialen Medien für das Modelltraining. Ein großer Teil der Feinabstimmung nach dem Training des Modells besteht darin, Grenzen und Filter zu setzen, damit das Modell nicht wiederholt, was es dort „gesehen“ hat.
- Weitere Beispiele für KI-Fehlschläge: https://www.privateinternetaccess.com/blog/ai-gone-wrong/
sind in der Regel mit Kosten verbunden, und diese Kosten steigen mit der Anzahl der Personen, die von diesen Misserfolgen betroffen sind oder sie wahrnehmen. Daher ist es für Unternehmen wichtig, die Herausforderungen zu erkennen, die mit der Implementierung dieser Technologien verbunden sind, sowie die potenziellen Kosten, die durch die Einführung einer schlecht oder gar nicht funktionierenden Lösung entstehen.
Bei der Arbeit mit maschinellen Lernmodellen müssen ethische Belange wie Fairness, Transparenz, Sicherheit und Datenschutz unbedingt berücksichtigt werden – und die Gesetzgeber beginnen bereits, dies zu tun:
- Die UNESCO hat im November 2021 mit der Recommendation on the Ethics of Artificial Intelligence’ den allerersten globalen Standard zur AI-Ethik vorgelegt. Dieser Rahmen wurde von allen 193 Mitgliedsstaaten angenommen.
- Die EU hat im Juni 2023 den EU AI Act verabschiedet, der die Nutzung von AI-Systemen in Europa regeln soll. Die Bewertung der potenziellen Auswirkungen dieser Vorschriften wird für jedes Unternehmen, das AI einsetzt, von entscheidender Bedeutung sein.
Der akademische und industrielle Sektor ist nicht weit davon entfernt. Die Einbeziehung ethischer Erwägungen in ihre Strategien ist inzwischen von größter Bedeutung. Ein aussagekräftiger Indikator ist der 2023 AI Index Report by Stanford University, in dem es heißt: “The number of accepted submissions to FAccT, a leading AI ethics conference, has more than doubled since 2021 and increased by a factor of 10 since 2018. 2022 also saw more submissions than ever from industry actors.”
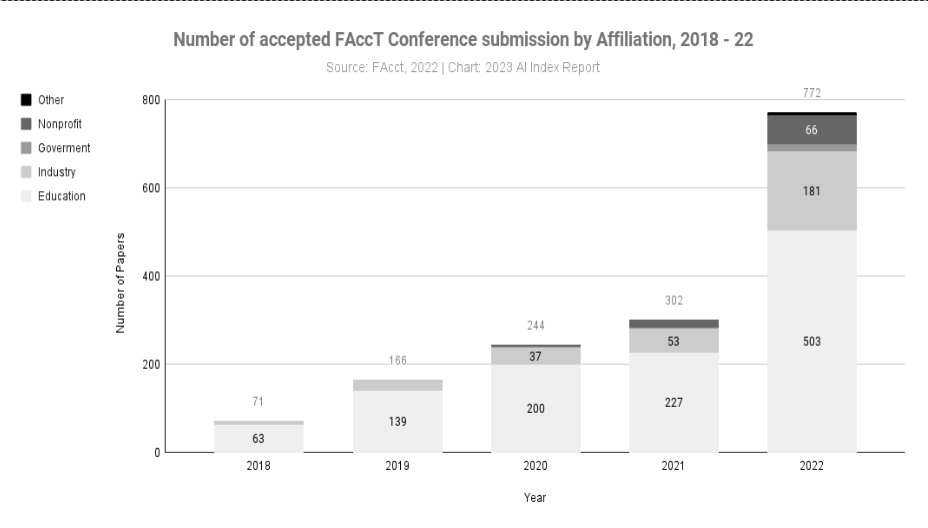
unterstreicht die zentrale Rolle der Ethik beim maschinellen Lernen. Im Jahr 2022 haben Blackman and Ammanath drei grundlegende Fragen formuliert, die sich jedes Unternehmen stellen sollte:
- Was sind die ethischen Standards unserer Organisation für KI?
- Wo stehen wir derzeit in Bezug auf diese Richtlinien?
- Wie können wir ein tiefes Verständnis für potenzielle Risiken erlangen und wie können wir diese Risiken eindämmen?
Durch einen ethischen Ansatz bei der Gestaltung von Data Products können Sie Produkte schaffen, die für die Nutzer und die Gesellschaft insgesamt wertvoll sind und gleichzeitig schädliche Folgen vermeiden.
FOMO um generative AI: Führen alle Wege zu großen Sprachmodellen?
Die Angst, etwas von der generativen AI zu verpassen, ist für viele Unternehmen so groß, dass sie angesichts der oben genannten Bedenken ihre Vorsicht in den Wind schlagen. Sie werden in den Strudel der AI-Innovationen hineingezogen, die täglich von verschiedenen Influencern und Medien veröffentlicht werden. Diese Geschichten zeichnen das Rennen zwischen großen Technologieunternehmen um das fortschrittlichste große Sprachmodell (LLM) und das Versprechen endloser neuer Geschäftsmöglichkeiten auf. Diese Hype-Welle wurde durch den Schritt von OpenAI ausgelöst, ihr LLM mit ChatGPT, einem Chatbot, der menschenähnliche Kommunikation ermöglicht, öffentlich zugänglich zu machen. zufolge besteht ihr LLM aus bis zu einer Billion Parametern und wurde auf einer riesigen Datenmenge (570 GB Text) aus verschiedenen Quellen wie Wikipedia, Büchern und dem Internet trainiert, um das nächste wahrscheinlichste Wort aus einer Liste von Wörtern, z. B. der Eingabefrage eines Benutzers, vorherzusagen.
Die Fähigkeiten der neuesten LLMs sind beeindruckend und ermöglichen Ihnen, um nur einige Beispiele zu nennen, folgendes:
- Programmiercode schreiben oder debuggen
- Zusammenfassen der Protokolle eines Meetings oder eines anderen Textes oder Audios
- Übersetzen zwischen verschiedenen Sprachen
- Inhalte für verschiedene Formate wie E-Mail, Apps und Blogartikel erstellen
- können bei jedem der oben genannten Themen und darüber hinaus als Co-Pilot agieren, indem Sie bei der Recherche helfen, ein bestehendes Konzept in Frage stellen oder einen Plan zur Entwicklung eines solchen vorschlagen.
Die Liste geht weiter und wird täglich aktualisiert. Sie reicht von der automatischen Erstellung von Folien bis hin zu AI-unterstützten Analysten, die in der Lage sind, selbständig Datensätze oder Screenshots von Dashboards und Bildern zu analysieren und zu interpretieren.
Neue Konzepte wie AutoGPT bringen sogar eigene AI-Agenten hervor, die autonom eine vorgegebene Aufgabenliste lösen und die bestehenden Funktionalitäten des LLM um die Möglichkeit des Zugriffs auf das Internet oder die Generierung und Ausführung von Python-Code erweitern. Microsoft hat gerade ein quelloffenes Python-Paket namens AutoGen veröffentlicht, mit dem Sie einen Workflow mit verschiedenen Agenten aufbauen können, die mit spezifischen Fähigkeiten und Rollen ausgestattet werden können.

Halluzinationen und Verkettungen: Was viele Menschen über AI vergessen
Dies sind beeindruckende und potenziell weltverändernde Fähigkeiten. Obwohl die Modelle immer besser werden, können sie auch zu „Halluzinationen“ neigen, d. h. sie denken sich Antworten aus, die falsch sind oder keinen Sinn ergeben. Bei den hitzigen Debatten und dem Marketing rund um AI sollten wir nicht vergessen, dass es sich um Sprach- und nicht um Wissensmodelle handelt. Diese Modelle haben kein Verständnis für die Welt und die Zusammenhänge verschiedener Themen, sind aber oft – aber nicht immer – verblüffend gut darin, die richtigen Wörter aneinander zu reihen.
Die Modelle haben unsere kognitive Fähigkeit, sie zu verstehen, umgangen, und die meisten ihrer Antworten auf die Fragen, die wir ihnen stellen, sind überzeugend eloquent. Aber sie sind nicht unbedingt richtig.
Große Suchmaschinenanbieter wie Google und Microsoft Bing haben den unglaublichen Aufstieg von ChatGPT von OpenAI beobachtet, das die am schnellsten wachsende Nutzerbasis in der Geschichte hat. Seitdem haben sie große Anstrengungen unternommen, um ihre eigenen Lösungen auf den Markt zu bringen. Sowohl Googles Bard als auch Bings AI haben viel Aufmerksamkeit erregt, aber die ersten Fehlfunktionen tauchten schnell in den sozialen Medien auf. Chatbot von Bing behauptete, sich in seinen Nutzer verliebt zu haben, und versuchte, ihn davon zu überzeugen, seinen Ehepartner zu verlassen. Bei einer anderen Gelegenheit weigerte er sich zu glauben, dass wir das Jahr 2023 haben und wurde ziemlich bissig gegenüber seinem Nutzer.
Auch wenn diese Beispiele lustig klingen, können Unternehmen ihren Ruf ernsthaft schädigen, wenn sie eine schlechte Lösung herausgeben. Dies gilt vor allem für die Internetsuche, bei der Google seit Jahren der dominierende Akteur ist. Fast alle großen Technologieunternehmen führen nicht nur die Texterstellung, sondern auch die Bild-, Audio- und Videoerstellung als Schlüsselelemente ihrer Produkte ein oder werden dies bald tun (Alexa ist auf dem Weg, LLM-gestützt zu werden, und dasselbe gilt für Apple mit AppleGPT).
Die hitzige Debatte darüber, was auf die Welt losgelassen wurde und wie dies das Internet für immer verändern wird, wird weitergehen und wir sollten ein informierter Akteur in diesem Prozess sein. Für einen kritischen Blick auf diese Entwicklungen empfehlen wir die Lektüre der Perspektiven von Gary Marcus oder Alberto Romero.
Wie können wir als Gesellschaft und als Einzelpersonen sicherstellen, dass der Weg der AI-Entwicklung mit ethischen Standards und dem gesellschaftlichen Wohlergehen in Einklang steht, während die großen Tech-Unternehmen ihr Rennen fortsetzen? Die Debatte ist noch lange nicht beendet, und die Entscheidung, welchen Weg wir einschlagen sollen, muss eher früher als später getroffen werden.
Auch wenn wir immer schneller neue Prototypen bauen, bleibt die Tatsache bestehen, dass ethische Diskussionen weiterhin wie ein Schatten über diesem Fortschritt liegen und dass 53 % der Projekte im Bereich des maschinellen Lernens nie in Produktion gehen. Wenn wir etwas bauen wollen, das für die Nutzer tatsächlich nützlich ist – und das auch im Laufe der Zeit nützlich bleibt -, müssen wir uns mit den schwierigen Fragen auseinandersetzen und offen sein für ein Umdenken, das uns hilft, Projekte über die Ziellinie zu bringen.
Zusammenfassung
Um maschinelle Lernsysteme in die Produktion zu bringen, müssen Unternehmen nicht nur technologische, sondern vor allem organisatorische Herausforderungen bewältigen.
In den kommenden Wochen werden wir die folgenden Schlüsselbereiche in speziellen Blogbeiträgen vertiefen und erfolgreiche Beispiele aus Kundenprojekten, häufige Fallstricke und natürlich mögliche Lösungen vorstellen:
- Reifegrad
- Strategie
- Modell-Entwicklung
- Bewertung
Wenn Ihr Unternehmen Unterstützung bei der Überwindung der in diesem Beitrag genannten Hindernisse benötigt, bietet unser Team von Datenexperten gerne Einblicke und Unterstützung bei der Einführung des maschinellen Lernens in die Produktion. Weitere Informationen zu unseren Dienstleistungen finden Sie hier, oder nehmen Sie hier Kontakt mit einem unserer Fachleute auf.